
The Retrieval Economy: 6 Things Your PDP Content Needs to Win in AI-Driven Commerce
5th May, 2026

By Vaibhav Khaparde
For two decades, a product detail page had one job: convince a human to click buy. Everything else, schema, alt text, structured feeds, was scaffolding. In 2026, the scaffolding is the job. Your PDP now spends most of its working hours being read by machines, and the machines reading it have started disagreeing with the search engines you spent fifteen years optimizing for.
The clearest signal is in the citation data. In mid-2025, roughly three out of four pages cited inside a Google AI Overview also ranked in the top ten organic results for the same query. By early 2026, that overlap had collapsed to between one in three and one in six, depending on whose dataset you trust. Ahrefs and BrightEdge land in different places, but both point in the same direction. Ranking and citation have decoupled. The implication is uncomfortable for anyone who built their AI visibility strategy on the assumption that strong SEO would carry them: it won’t, and it isn’t.
Meanwhile, the channel itself has stopped being marginal. Adobe’s analysis of more than a trillion U.S. retail visits showed AI-driven traffic up 4,700% year over year in July 2025, and up 693% during the 2025 holiday season. More importantly, the conversion gap reversed. Through early 2025, AI-referred shoppers were 9% less likely to convert than traditional channels. By October 2025, they were 16% more likely. The channel is now fast-growing and high-quality. The rules for winning in it just aren’t the rules you know.
This piece is about what those rules actually are. Not a checklist (there are enough of those), but an argument about what’s structurally different and what to do about it.
Three Audiences, Three Retrieval Mechanisms
The thing most PDP playbooks get wrong is treating “AI” as a single audience. It isn’t. Your product page now serves at least three distinct retrieval surfaces, and each one reads it differently.
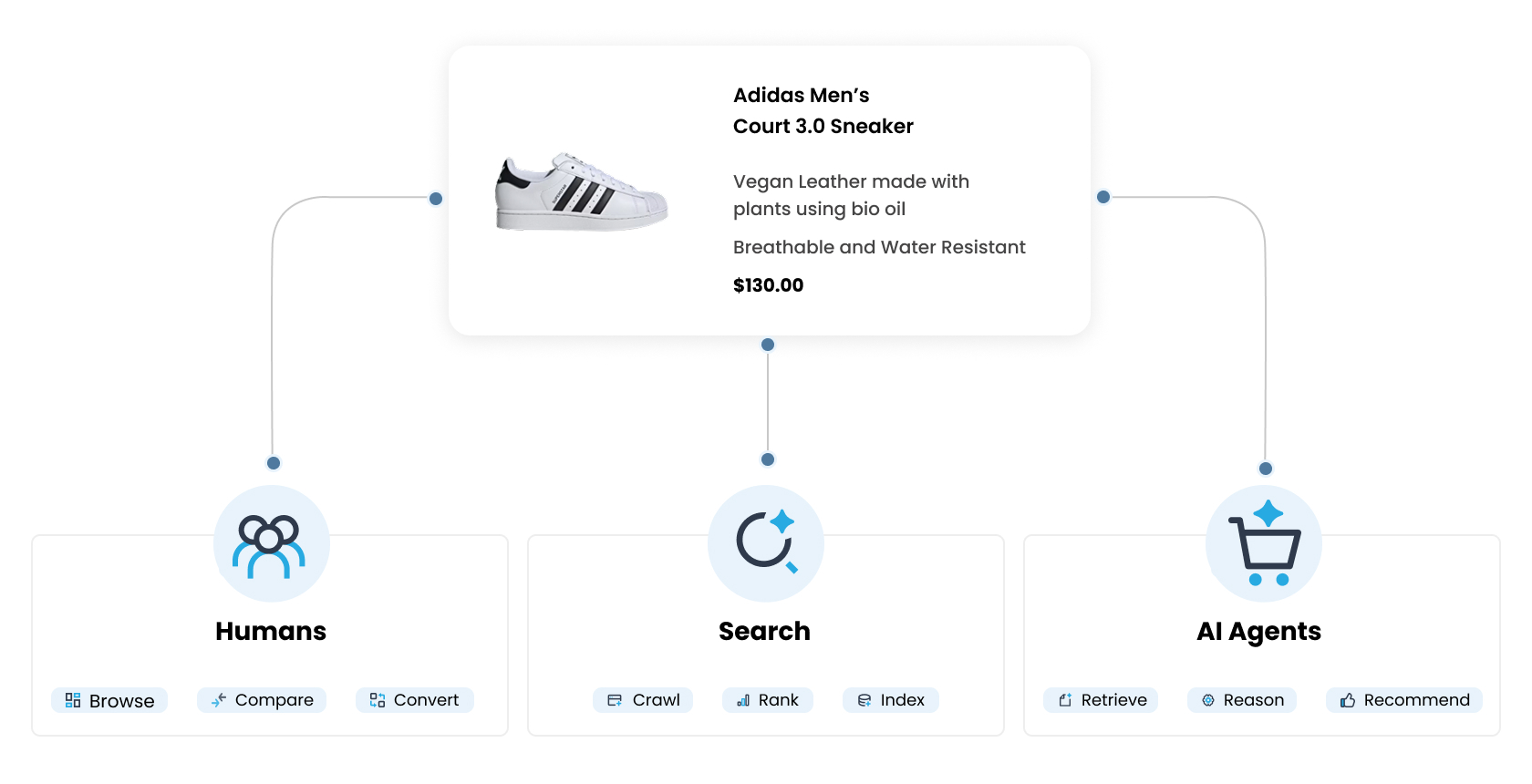
- Chat-based research (ChatGPT, Perplexity, Claude) fetches your live page when the model decides it needs current information. These pipelines parse rendered HTML. They mostly do not read JSON-LD payloads at retrieval time. What matters here is whether your content is server-side rendered, dense, and answer-first within the first few hundred tokens.
- AI Overviews and AI Mode (Google, Bing, Copilot) operate on a hybrid of crawled content and structured data. Google explicitly states no special schema is required to be cited, but structured data helps classical ranking, which still feeds AI Mode upstream. Schema’s role here is indirect but real.
- Agentic checkout (UCP, ACP, ChatGPT Instant Checkout, Gemini Shopping) is the surface where structured data is load-bearing. Real-time offer schema, accurate inventory, GTINs, shipping and return policy fields, these are the difference between being included in the agent’s purchase recommendation and being filtered out of it. Google’s Universal Commerce Protocol launched at NRF in January 2026 with Shopify, Walmart, Target, Etsy, Wayfair, and twenty more endorsers. OpenAI’s Agentic Commerce Protocol, built with Stripe, powers ChatGPT Instant Checkout. These are the distribution rails your catalog plugs into or doesn’t.
A PDP strategy that treats these three as one will over-invest in the wrong layer, typically by pouring resources into schema markup while ignoring whether the rendered HTML is even readable to the agents fetching it.
The Retrieval Economy
The deeper shift is economic. Every time an AI agent retrieves your PDP, it pays a cost in tokens, latency, and attention budget. RAG pipelines, the architecture behind almost every AI shopping experience, don’t ingest entire pages. They retrieve chunks, typically capped at two or three per source. If the spec that would have won the recommendation isn’t inside the chunk that gets selected, that spec functionally doesn’t exist for the agent.
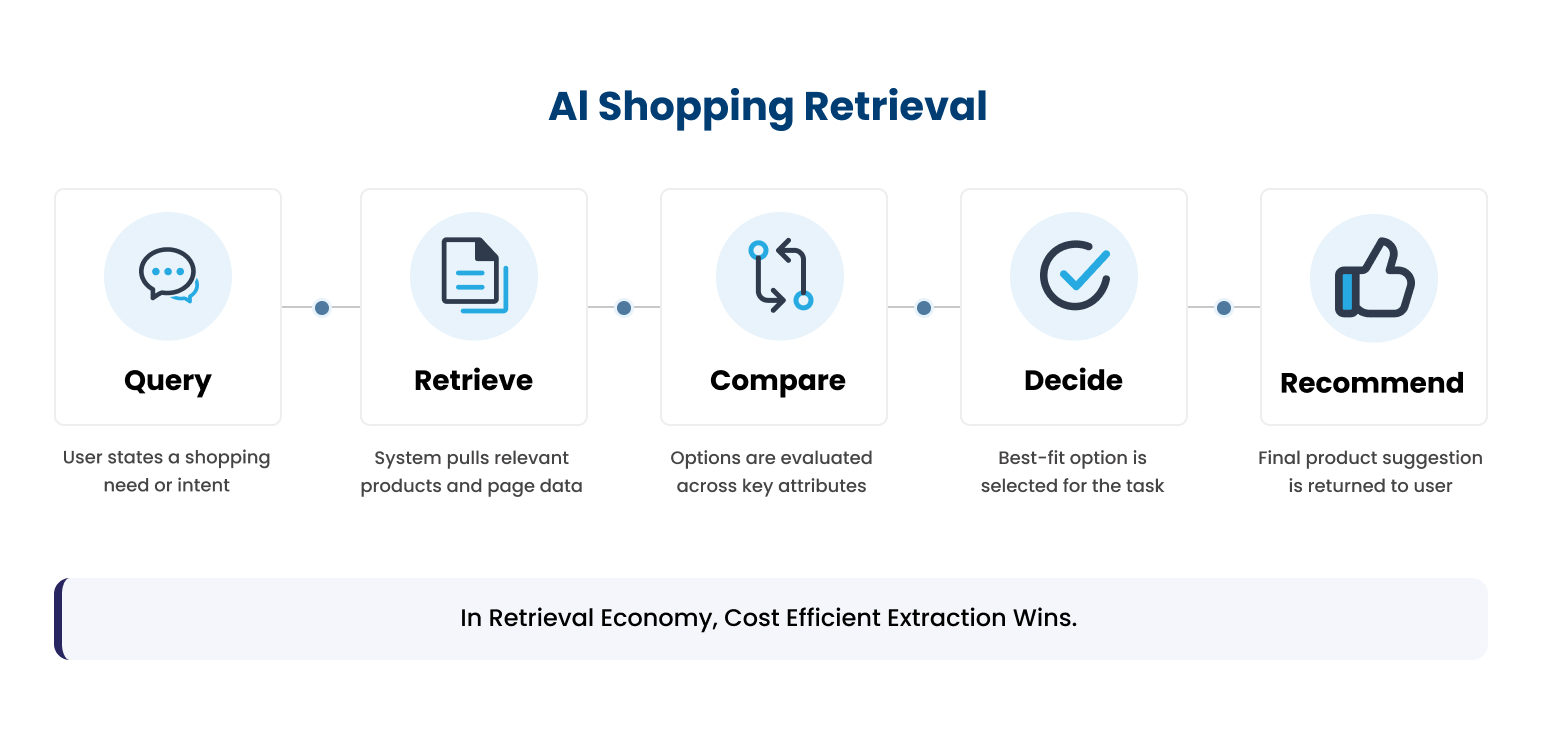
At the scale agentic shopping is moving to (millions of product comparisons per day across every major AI platform), engineering teams are actively optimizing to fetch less, rank harder, and reject low-density sources. A 4,000-token PDP packed with marketing prose, repeated specs across multiple tabs, and JS-rendered content the bot has to wait for is structurally more expensive to evaluate than a competitor’s 800-token, dense, semantically clean equivalent. Over time, the expensive page loses.
The PDPs that win citation share in 2026 are not the longest, the prettiest, or the most keyword-dense. They’re the cheapest to extract correctly. That’s the part of the AEO conversation almost nobody is having yet.
The Six Things That Actually Move The Needle

Most PDP optimization advice in 2026 is still framed around what the page contains. The retrieval economy reframes it around what the page costs to extract. Once you accept that reframe, the priority list shrinks fast.
1. Crawler Access
This is the most underrated failure mode in the entire AEO conversation. Cloudflare changed its default in July 2024 to block AI crawlers. A meaningful percentage of brands have unknowingly turned off ChatGPT, Perplexity, and Google-Extended access to their own catalogs. Adobe’s AI Content Visibility Checker found that roughly a third of retailer PDPs can’t be properly accessed by AI crawlers at all.
Add to this the JavaScript rendering problem. AI crawlers don’t execute JS reliably. Anything inside an accordion, a tab, a “read more” toggle, or a client-side rendered framework that doesn’t server-side render is functionally invisible to most retrieval pipelines.
The fix isn’t usually a rebuild. It’s a robots.txt audit and a render-mode audit, in that order. Confirm GPTBot, OAI-SearchBot, PerplexityBot, ClaudeBot, and Google-Extended are not blocked. Confirm your most important content (specs, pricing, availability, attributes) lives in the initial HTML response, not behind a JS interaction.
2. Render-Time Content Density
Density beats volume. The instinct on most PDP teams, born from a decade of SEO advice to add more content, more H2s, more semantic variations, is exactly wrong for the retrieval economy. The same fact stated once in a structured way beats the same fact restated three times in adjacent paragraphs.
Format matters too. JSON-LD, tables, and tightly structured bullet lists tokenize more efficiently than equivalent prose. “Battery life: 40 hours” is three or four tokens. “This product offers an impressive battery life of up to 40 hours of continuous use on a single charge” is closer to twenty, carrying the same factual payload. Replace marketing prose with attribute tables wherever you can.
And order matters. Whatever sits in the first 500 tokens of your rendered HTML is what agents weight most heavily. “Lost in the middle” is a documented degradation pattern: facts placed in the middle of a document get recalled less reliably than facts at the start or end. Hero banners, navigation chrome, and breadcrumb trails that delay the actual product information are taxing your retrievability without helping anyone.
A useful test: pull a representative sample of your PDPs, count their rendered token length, and compare against the same metric on competitors most often cited in AI answers for your category. If your pages are three to four times longer for the same factual content, you have a density problem, not a content gap.
3. JSON-LD for Entity Persistence
Schema markup matters, but for a different reason than most PDP teams assume. It is not the lever that determines whether you get cited in tomorrow’s ChatGPT answer. Live retrieval pipelines mostly read rendered HTML. Where JSON-LD does load-bearing work is at training time. When models are retrained, structured data gets converted into natural-language statements during data preparation, embedding brand and product facts into model weights. The payoff is months out, and shows up as the model “knowing” your products without having to fetch them.
For agentic checkout (UCP, ACP), JSON-LD moves from second-order to required. Real-time offer schema, GTINs, MPNs, brand and organization markup, these are the fields agents read directly to surface a purchase recommendation.
The practical posture: full schema.org/Product nesting on every PDP, validated against Google’s Rich Results Test, kept in parity with what’s visible on the page.
4. Real-Time Offer Schema
This is the gate to agentic commerce. Price drift between your PDP, your schema, and your Merchant Center feed is one of the most common reasons for listing disapproval and exclusion from AI shopping recommendations. The standard isn’t “accurate within the day.” It’s “accurate at the moment of the agent’s call.”
Include price, priceCurrency, availability, itemCondition, shippingDetails, and returnPolicy in your Offer schema. Sync inventory in real time. Match pricing exactly between schema, on-page display, and feed. If your warehouse shows zero, your schema needs to update the same minute. Agents that cross-check and find drift treat your listing as untrusted and route around it.
This is a data infrastructure problem, not a content problem. Brands that solve it pull ahead of competitors with better marketing copy but slower data pipelines.
5. Earned Media for Citation Lift
PDPs don’t win citation share alone. The Princeton GEO research published at SIGKDD 2024 (Aggarwal et al., “GEO: Generative Engine Optimization”) tested specific content interventions and measured their effect on citation probability inside generative engines. Adding expert quotes lifted citation probability by roughly 41%. Adding statistics lifted it by roughly 30%. Adding citations to authoritative sources lifted it by roughly 30%. Keyword stuffing actively hurt performance, with a 9% decline.
Separate analyses from Muck Rack and University of Toronto researchers point in the same direction: AI engines cite earned media (Reddit threads, review sites, category publications, expert roundups) at substantially higher rates than brand-owned content for the same products.
The brands compounding citation share are also seeding authoritative third-party content in the venues AI systems already trust. Track which external sources are cited for products in your category. Treat citation frequency in those venues as a leading indicator of AI-driven revenue.
6. Content Parity Across Surfaces
This is where most implementations quietly fail. Your JSON-LD says the price is $49.99. Your rendered page says $52. Your Merchant Center feed says $49. Your Amazon listing says $48.99 with different bullets and a different title. AI systems and agentic surfaces cross-check across endpoints, and treat mismatches as a trust signal failure.
Parity isn’t just a price problem. It’s a description, attribute, claims, and image problem. Every surface where your product appears is being read against every other surface. Drift on any one dilutes the signal everywhere else.
The structural fix is to treat your product data as a single source of truth that emits multiple representations: rendered HTML for humans and chat-based retrieval, JSON-LD for entity persistence and classical ranking, structured feeds for UCP and ACP checkout, and (emerging fast) markdown summaries via llms.txt for systems that want to skip the page entirely. The brands maintaining these as four separate workflows will fall behind the brands generating them from one canonical record.
This is the deepest operational shift in the list, and the one most legacy PIM and CMS architectures aren’t built for.
The New Operating Model
Optimizing PDPs at catalog scale requires a different operating model than the quarterly content audit most teams still run. One canonical record per SKU, multiple representations generated downstream, drift detected and reconciled automatically. This is the gap our Content Optimization solution is built to close: continuous PDP audits across every surface where your products are listed, AI-generated copy compliant with retailer rules and category attributes, parity monitoring across HTML, schema, and feeds, and content health scoring against actual category leaders. The flywheel (audit, benchmark, prioritize, optimize, publish, monitor, iterate) replaces the project model that breaks down past a few hundred SKUs.
The other shift is measurement. Citation share is the new leading indicator. It moves before traffic does, and well before revenue does. Profound, Otterly, and a handful of newer tools are building toward this category. Manual sampling against a defined query set still works for most teams.
The brands that internalize this shift in 2026 will compound a citation-share advantage that’s very hard to dislodge later. The brands still treating their PDPs as marketing pages with schema bolted on will spend the next two years wondering why their organic traffic looks fine and their AI visibility doesn’t.
For the full framework and how you can implement it, talk to us.




Book a Demo
Login
For accounts configured with Google ID, use Google login on top.
For accounts using SSO Services, use the button marked "Single Sign-on".