
AI Shopping Can’t Scale Until Product Data Stops Being a Mess
18th Mar, 2026

By Karthik Bettadapura
OpenAI’s push to turn ChatGPT into a go-to shopping assistant is a glimpse into the next major interface shift in commerce. Consumers are already using AI to explore products, compare options, and narrow down choices. The natural next step is obvious: if an AI can recommend what to buy, why shouldn’t it also help you buy it?
But recent developments show how hard that transition actually is.
In OpenAI’s Shopping Ambitions Hit Messy Data Reality, The Information highlighted how fragmented and inconsistent product data slowed early efforts to enable in-chat checkout. More recently, OpenAI’s Shopping Glitch pointed to a broader pullback from direct transactions, while OpenAI’s Betting on ChatGPT Apps—but People Need to Find Them First shows that even alternative approaches like app-based commerce are struggling with adoption and conversion.
These aren’t just product missteps. They are signals of a deeper issue.
The challenge isn’t whether AI can guide shopping. It’s whether it can reliably act on product data.
Pricing and availability are spread across multiple systems. Inventory definitions vary. Product details are incomplete or inconsistent. And the risk is real: if an agent reads a signal incorrectly, or interprets it in the wrong context, it might charge the wrong price or attempt to buy something that is actually out of stock.
These are not edge cases or rare occurrences. They are the core bottleneck to scaling agentic commerce.
And importantly, they don’t change the direction of where things are headed.
AI-driven transactions are inevitable.
What’s changing is not whether AI will enable purchases, but what needs to be solved before it can scale reliably.
As AI search engines and assistants increasingly enable shopping – whether by surfacing product recommendations, generating “best options” lists, or eventually executing purchases – the one thing they cannot afford is unreliable data.
To make AI shopping work at scale, the industry has to solve a fundamental requirement:
Aggregate the world’s product data and harmonize it into a complete, accurate, and comparable view of the shelf, in a timely manner and at scale.
In short: make product data AI agent ready.
That sounds simple. It isn’t. But it’s exactly what the next phase of AI commerce depends on.
Recommendation is easier. Transaction requires truth.
AI models are great at language. They can synthesize reviews, summarize product specs, and explain tradeoffs. But commerce isn’t just language, it’s a constantly changing system of record.
The moment an AI transitions from “helpful guide” to “shopping agent,” it stops being judged on how smart it sounds and starts being judged on whether it’s correct:
- Is the price current?
- Is the item actually available?
- Is this the exact variant the user asked for?
- Can we compare two items fairly across sellers?
- Will the merchant honor the order without disputes?
A recommendation engine can survive occasional uncertainty. An odd surprise could even lead to interesting recommendations. A purchasing agent, however, must not cause surprise. It has to be predictable.
That’s why the “messy data reality” matters beyond OpenAI. It’s a warning signal for the entire ecosystem: AI shopping won’t be governed by the sophistication of the model alone. It will be governed by the quality of the underlying data that the model is acting on.
The real challenge: harmonizing commerce data across a fragmented world
Commerce data is fragmented by default. Every merchant stack looks different. Every retailer and marketplace uses its own taxonomy. Even when two sellers offer the exact same product, they may describe it differently, price it differently, and report availability differently.
Normalization is the process of turning that chaos into something structured, consistent, and comparable.
And to normalize properly for AI-driven decisions, three requirements have to be true at the same time:
1) Real-time access with massive coverage
Agentic commerce is not nearly effective with stale snapshots. Prices change daily, sometimes hourly. Inventory shifts constantly. Promotions launch and end on a schedule that rarely aligns across channels.
If an AI assistant is expected to produce “the best options right now” or execute a purchase in-chat, the data feeding it must be continuously refreshed across:
- retailer sites and marketplaces
- D2C brand sites
- regional variations and store-level conditions (where relevant)
- promotions, bundles, and “hidden” pricing rules
Coverage matters as much as freshness. Partial data leads to partial truth, and partial truth leads to poor experiences and merchant distrust.
2) Reliable data quality and veracity
Commerce data is noisy:
- pages change layout
- product identifiers get reused
- descriptions are incomplete
- inventory states are ambiguous (“in stock” vs “preorder” vs “backorder”)
- prices can be displayed differently for different users
When AI agents rely on this data, errors are not just inconvenient. They create payment disputes, returns, and brand damage.
To scale agentic commerce, the ecosystem needs a data layer that not only collects signals, but also enriches and validates them, Such a layer should also have: (a) the ability to self-detect (and self-correct, at least in parts) any data quality problems, (b) explainability and transparency, and (c) an audit mechanism.
3) Annotated and labeled data for harmonization and comparison
Harmonization entails understanding the semantics of every retail vertical and the context of every SKU.
To compare products across sources, AI systems need labeled intelligence:
- product matching and entity resolution (this SKU on Retailer A equals that listing on Retailer B)
- attribute extraction and standardization (size, pack count, color, ingredients, model number)
- taxonomy alignment (category mapping across retailers)
- availability interpretation (what “in stock” actually means in a given context)
- promotion labeling (sale vs everyday price vs coupon vs bundle)
This is the part many teams underestimate. Even with a protocol for transactions, the agent still needs clean product truth to decide what to buy, from whom, and when.
Protocols help agents transact. Normalization helps agents decide correctly.
Why apps don’t solve the problem
In response to these challenges, the industry is experimenting with alternatives like apps within ChatGPT or redirecting users to merchant storefronts.
But these approaches don’t fundamentally change the shopping experience.
They reduce friction marginally, saving a click or two, but they do not solve the core problem: AI systems still lack a unified, reliable view of product data.
As a result:
- product listings appear inconsistently
- product coverage remains limited
- conversion rates remain low
- merchant onboarding remains manual and slow
These are not interface problems. They are data problems.
Apps represent a transitional layer. The end state is clear: AI systems that can surface the right products and enable transactions directly within the experience.
But that only works when the underlying data is normalized, comparable, and trustworthy.
Why this matters for everyone, not just OpenAI
The implications go well beyond one company’s roadmap. If AI becomes the front door to commerce, then:
- AI platforms need accurate, comparable product truth to protect user trust and reduce transaction disputes.
- Merchants and brands need control and confidence that their products are represented correctly and competitively.
- Marketplaces need scalable ways to make millions of catalogs agent-ready without endless manual onboarding.
- Payment providers need fewer exceptions and fewer disputes, because “bad data” turns into costly operational overhead.
In other words: as AI shopping grows, the data normalization layer becomes shared infrastructure, like payment rails or search indexing.
The winners will not just be the companies with the best agents. They will be the companies that ensure agents can act on reliable commerce truth.
DataWeave’s Role: The Perception Layer for Agentic Commerce
That’s the gap DataWeave fills. We focus on the foundational work that makes agentic commerce possible: transforming fragmented, fast-changing retail signals into structured, comparable intelligence at scale.
If agentic commerce is the decision-making layer, DataWeave is the perception layer – the system that continuously observes the shelf, standardizes it, and makes it usable by AI agents.
But in an agentic commerce environment, making data “usable” is not just about structure. It’s about enabling AI systems to correctly interpret what a product is, how it compares to alternatives, and whether it can be acted on with confidence.
DataWeave doesn’t just normalize data. It enables AI systems to understand, compare, and act on product information across fragmented sources. That means resolving ambiguity in product attributes, aligning context across retailers, and ensuring that what an agent sees is not just clean, but decision-ready.
What a data backbone means in practice
A true agentic commerce backbone must be able to:
- Timely Price and Availability at Scale: Collect and refresh product, price, availability, and content signals across vast coverage
- Product Matching and Identity Resolution: Match and unify products across sources into consistent entities
- Data Harmonization: Normalize and enrich attributes so products are comparable
- Data Labeling: Interpret ambiguous signals into action-ready truth
- Reliable Data Delivery: Deliver AI-ready intelligence via APIs and pipelines that agents can reliably consume
The capabilities that make DataWeave agentic-commerce ready
Let’s get specific about the capabilities that matter most for the challenges described in the article.
1) Timely price and availability intelligence at scale
For AI shopping, the most immediate failure modes are wrong price and wrong availability.
DataWeave continuously tracks these signals across large catalogs and retailer sets, enabling:
- near real-time updates
- change detection (what shifted, when, and where)
- consistent reporting across sellers and channels
This gives AI platforms and merchants a more reliable view than “best-effort scraping” or merchant-provided feeds alone, especially when those feeds are incomplete, delayed, or inconsistently structured.
2) Attribute extraction, normalization, and taxonomy alignment
When product content varies by source, the agent needs standardized attributes to reason correctly.
DataWeave extracts and normalizes key fields such as:
- pack sizes and unit counts
- weights and dimensions
- variant attributes (color, flavor, size)
- product specifications and structured descriptors
- category mappings across retailers
This is what enables apples-to-apples comparisons across sources, even when the underlying source data is messy or incomplete.
For Example:
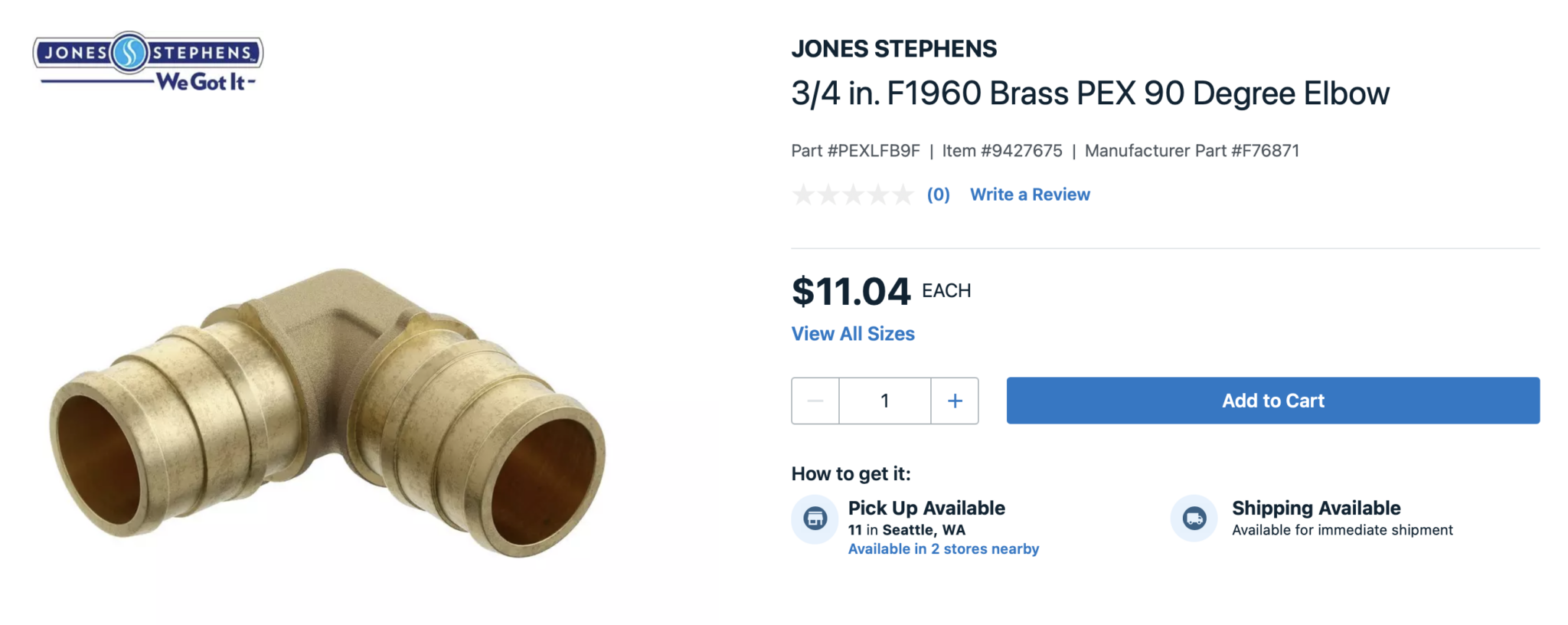
The system should understand:
- Product Category → Pipe fitting (not pipe, not valve, not adapter)
- Fitting Type → 90° elbow (directional change fitting)
- Angle Geometry → 90° (not 45°, not tee, not coupling)
- Nominal Size → 3/4 inch PEX standard size (nominal, not literal OD)
- Pipe System → PEX plumbing system (not copper, CPVC, PVC)
- Connection Standard → ASTM F1960 (expansion-type fitting)
- Compatibility Rule → F1960 ≠ F1807 (crimp system mismatch)
- Material → Brass (not polymer, not stainless)
- Full-size vs Reducing → 3/4″” x 3/4″” (not 3/4″” x 1/2″”)
Why PDP content becomes critical in an AI-driven world
As AI systems increasingly influence discovery and decision-making, PDP content is no longer just for human shoppers. It becomes the primary input for AI reasoning.
Missing attributes, inconsistent naming, or weak descriptions don’t just affect user experience. They directly impact whether a product is surfaced, how it is interpreted, and how it is compared.
In an agentic commerce environment:
- incomplete content reduces visibility
- inconsistent content breaks comparability
- poor structure limits AI understanding
- Content quality becomes data quality.
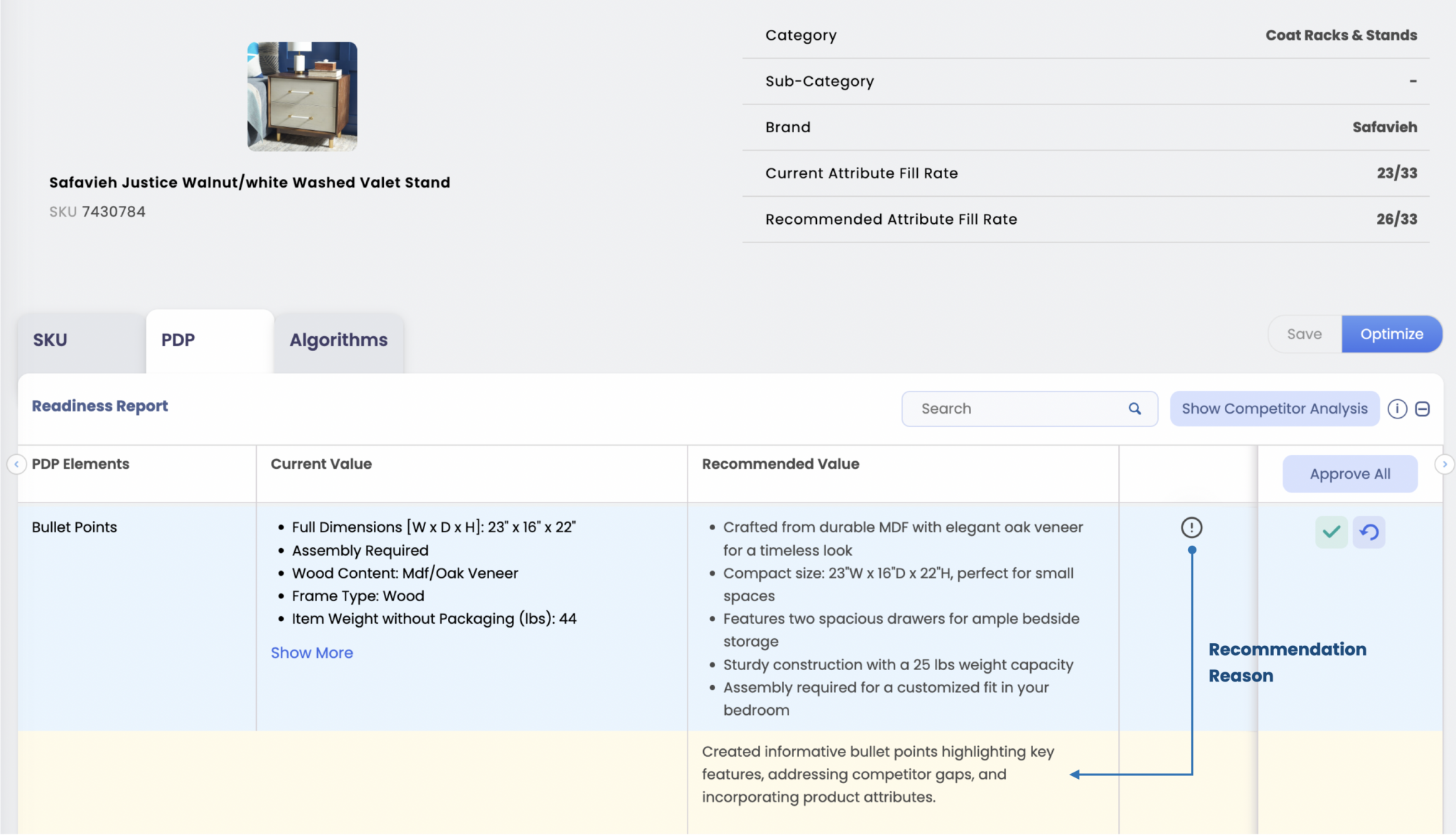
Inside the DataWeave Dashboard
All of these capabilities come together to help retailers deliver context-rich, conversion-driving product content that stands out on the digital shelf.
DataWeave’s Content Optimization solution analyzes existing PDP content to identify attribute gaps, inconsistencies, and content quality issues. It then provides actionable recommendations to improve accuracy, strengthen attribute coverage, and refine product messaging so listings are more complete, comparable, and optimized for conversion.
3) Product matching and identity resolution across sources
Before an agent can compare two offers, it needs to know whether it’s comparing the same thing.
DataWeave’s matching systems connect listings across retailers, marketplaces, and brand sites, creating a unified product identity layer. That matters for:
- true price comparison (same product, different sellers)
- variant accuracy (correct size/color/model)
- avoidance of duplicates in AI recommendations
- consistent attribution and analytics
Example 1: Text Analysis
Original Title: Fresh Chicken Breast Boneless Skinless 500g
Comparison SKU Title: Chicken Fillet 0.5 kg – No Skin, No Bone
The system should understand:
- Chicken Breast ≈ Chicken Fillet
- Boneless ≈ No Bone
- Skinless ≈ No Skin
- 500g ≈ 0.5 kg
- “Fillet” in the poultry context often refers to the breast portion
- Processing attributes (boneless, skinless) must align
- Unit normalization is required
- Fresh vs Frozen distinction (if reference says frozen → Not match).
Example 2: Image-based Exact and Similar Matching
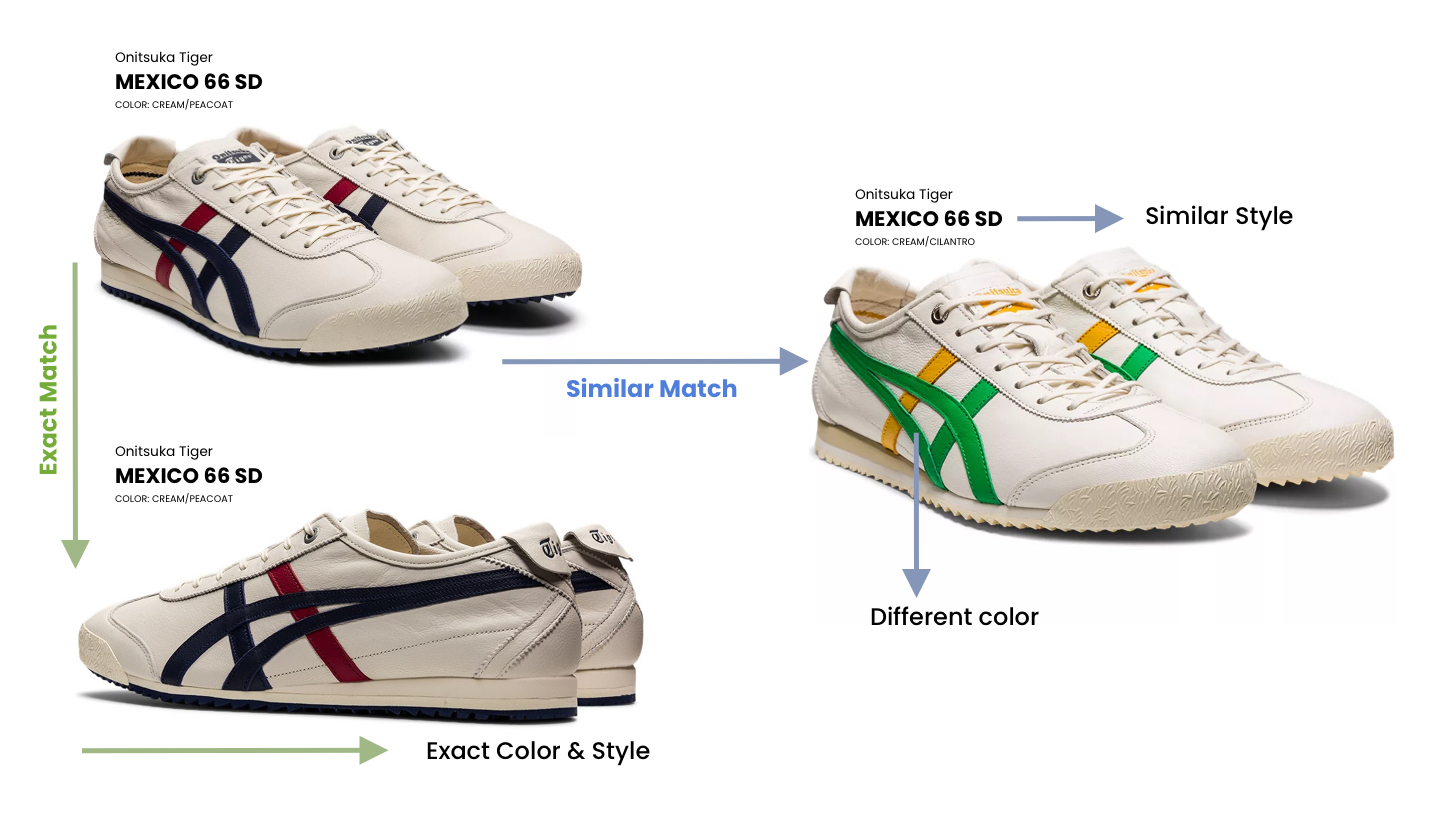
Example 3: Similar and Substitute Matching


This is a cornerstone of normalization. Without it, agents make false comparisons and produce unreliable rankings.
4) Interpreting and labeling ambiguous availability states
One of the article’s most telling examples is that “in stock” can mean different things. Sometimes it means backorder. Sometimes it means preorder. Sometimes it’s technically available, but not deliverable in the user’s region.
Agentic commerce needs availability states that are interpretable and action-ready.
DataWeave can support this by:
- mapping retailer-specific inventory language into standardized states
- labeling edge conditions (preorder, backorder, limited stock, delayed fulfillment)
- incorporating additional signals when needed (shipping messaging, lead times, fulfillment constraints)
That reduces failed checkouts and reduces the risk of disputes.
5) Promotion and pricing context, not just price
Agents won’t just compare price. They’ll compare value.
A discount might be:
- a temporary sale
- a coupon requirement
- a bundle offer
- a loyalty-only price
- a subscribe-and-save structure
DataWeave captures promotional context and helps structure it into comparable intelligence, so agents don’t misrepresent savings or recommend misleading “best deals.”
6) Delivery as an AI-ready intelligence layer
Finally, agentic commerce requires delivery mechanisms that can plug into AI systems cleanly:
- APIs for real-time retrieval
- feeds for scheduled updates
- structured outputs that align with agent frameworks
- consistent schemas across categories and sources
This is where DataWeave becomes infrastructure, not just analytics. It becomes a reliable input layer for any agentic commerce system, whether that’s a conversational assistant, a marketplace shopping agent, or a brand’s own AI concierge.
A simple framing: protocols are necessary, but not sufficient
The ecosystem is right to develop transaction standards and protocols. They will help agents communicate with merchant systems correctly.
But protocols don’t fix messy product truth.
The missing layer is normalization. And normalization requires: real-time coverage, reliable quality, and labeled intelligence that makes cross-source comparison possible.
That’s where DataWeave enables the ecosystem, and why this moment is an inflection point for commerce intelligence
From AI Ambition to AI Commerce Reality
AI shopping won’t scale on intelligence alone. The real constraint is whether agents can act on data that is current, comparable, and trustworthy across sources. Recommendations can tolerate ambiguity. Transactions cannot.
As AI search engines move closer to enabling purchases, the normalization layer becomes decisive. Product data must be collected in a timely manner, validated for accuracy, and labeled so that pricing, availability, and attributes can be interpreted consistently before any decision is made.
That’s the role DataWeave plays. By unifying collection, product matching, normalization, and labeled intelligence into a single pipeline, DataWeave provides the commerce truth that agentic systems depend on.
If you’d like to dive deeper, the DataWeave team is just a conversation away.




Book a Demo
Login
For accounts configured with Google ID, use Google login on top.
For accounts using SSO Services, use the button marked "Single Sign-on".