
Real-Time Competitive Intelligence: How a Leading North American Retailer Transformed Its Merchandising Benchmarking Workflow
27th Apr, 2026

By Vikranth Ramanolla
Merchandising teams often struggle with quick, accurate visibility into what competitors are doing across retailers. Answering questions like what’s selling, at what specs, at what price, and how it stacks up against their own catalog in real-time can be a challenge.
The data exists. It’s sitting on retailer websites, in product listings, in ratings and specifications and descriptions. But pulling it together, normalizing it, making it actually comparable across multiple sources – all in real time? That’s where the process falls apart.
For a leading North American retailer with thousands of SKUs across dozens of categories, this was the gap they set out to close.
What They Actually Needed
The retailer’s core requirement was straightforward: the ability to enter a search query and get populated and normalized spec data. In practice, that meant:
- A user selects the retailers they want to benchmark against and enters a product keyword or category.
- The system returns the top organic results from each retailer, with sponsored placements identified and filtered out.
- For each result, it extracts pricing, ratings, review counts, and product specifications.
- All attributes are normalized using AI across sources so they’re directly comparable without manual cleanup.
- The output is a structured file (Excel or CSV) that feeds straight into internal planning workflows.
- Most importantly, all of this needs to happen in a matter of minutes, not hours or days.
Beyond the core ask, the retailer also needed the solution to work across both hard goods and soft goods, include their own listings alongside competitors for direct comparison, offer sortable and filterable results (by rating, best-selling, and other criteria), and scale to support multiple concurrent users running simultaneous queries.
Simple to describe. Hard to build. Because retail product data isn’t standardized. Every retailer structures its pages differently, uses different taxonomies, and displays specifications inconsistently, sometimes even within a single site. A field called “tank capacity” on one site might be labelled “reservoir size” on another. What one retailer lists as a feature bullet, another buries in a secondary spec table. Pricing formats, rating scales, review counts: none of it aligns neatly across sources.
Layer in anti-bot mechanisms, dynamic content rendering, rate limits, and constant site structure changes, and you start to see why maintaining a reliable data pipeline for this kind of use case wasn’t feasible for the retailer’s internal teams. They needed a partner who’d already solved these problems at scale.
The DataWeave Approach
The retailer partnered with DataWeave to deploy a self-serve competitive intelligence platform, the first of its kind in DataWeave’s product lineup. This platform places the controls directly in users’ hands. Category managers, stakeholders, and merchandising teams log in, run their queries, and get structured outputs on their own terms.
The platform is built around two complementary services, each designed for a different workflow.
Real-Time Data Collection
This is the foundation. DataWeave’s Data Collection API solution gives managers direct, on-demand access to competitive product data across multiple retailers and geographies, delivered through a dashboard they control entirely on their own.
The platform supports three search modes:
- Quick Price Check: Users enter specific UPCs and the system checks pricing for those products across competitors. This is the mode for teams that already know what they want to watch and need a fast, reliable read on how their pricing compares against the same products elsewhere.
- Category Scan: Users enter a product category and the system returns a full overview of products available in that category across the competitive landscape. This mode is particularly useful when a team is exploring a new product type they don’t currently carry. If a stakeholder wants to understand the air purifier market before recommending it for onboarding, they can run a category scan across competitors and get a full picture of what’s out there, what’s selling, and at what price points.
- Multi-location Check: Users select key SKUs and the system monitors them across multiple ZIP codes or store locations, surfacing geographic variation in pricing, availability, and assortment. This is the mode for teams that need visibility not just across retailers but across regions and individual stores.
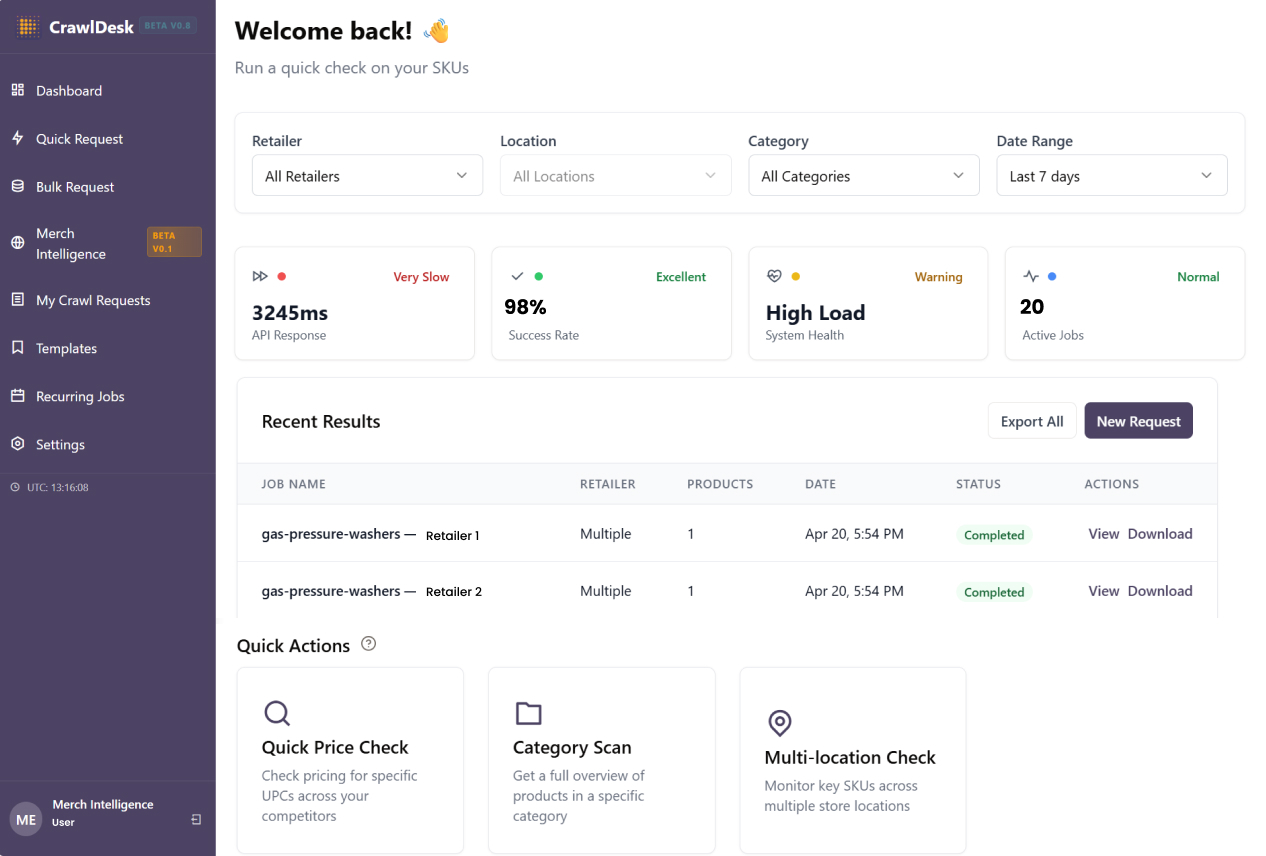
All three modes can be run as a one-time crawl for a quick snapshot or set up as scheduled jobs that deliver fresh data on a recurring basis (daily, weekly, or whatever cadence the team needs). With a scheduled job, users get an ongoing feed that surfaces what matters most: latest pricing across retailers, new products being introduced to the market, shifts in availability, and changes in ratings or review volume. Essentially, a structured view of everything that’s happening on the digital shelf across their tracked categories and SKUs, updated on their schedule.
What comes back is a data feed pulled from live retailer pages as they appear to consumers, reflecting real market conditions rather than stale or cached snapshots.
A few things worth calling out about how the Data Collection API works:
- Near real-time speed: Crawl jobs complete in 1.5 to 5 minutes depending on scope. Fast enough to run during a planning meeting and have results before the conversation moves on.
- Fully self-serve: Users set up and manage their own crawl jobs without involving DataWeave’s team. They can create jobs, modify parameters, adjust schedules, and pull results directly from the dashboard. No tickets, no analyst dependencies.
- Built-in alerting and auto-recovery: The platform notifies users when jobs complete and handles failures intelligently. Crawling at scale means occasional blocking and rate limiting from retailer sites, and many of these issues are transient. The system uses smart retry logic to recover automatically from these failures rather than simply returning incomplete data and leaving users to figure out what went wrong.
- Multi-retailer, multi-geography coverage: Crawls can span multiple retailers, ZIP codes, and store locations simultaneously, so teams get a complete competitive picture without stitching together separate data pulls.
- Structured, ready-to-use output: Data comes back normalized and formatted for direct use in internal workflows, whether that’s feeding a planning spreadsheet, a BI dashboard, or a product development brief.
For teams that have been relying on manual searches, periodic vendor reports, or brittle internal scrapers, the Data Collection API replaces all of that with a single, reliable, always-current data source they control themselves.
Merch Intelligence: AI-Powered Competitive Analysis
Built to complement the data collection API, Merch Intelligence is designed for merchandising teams who need more than just data. They need structured competitive intelligence that helps them decide which products to onboard, where spec gaps exist, and how their catalog compares to the market.
Merch Intelligence is powered by DataWeave’s proprietary AI engine, and this is where the distinction matters. Unlike general-purpose AI tools, DataWeave’s engine is built for retail, trained on years of category-specific patterns across millions of product records and hundreds of retailers.
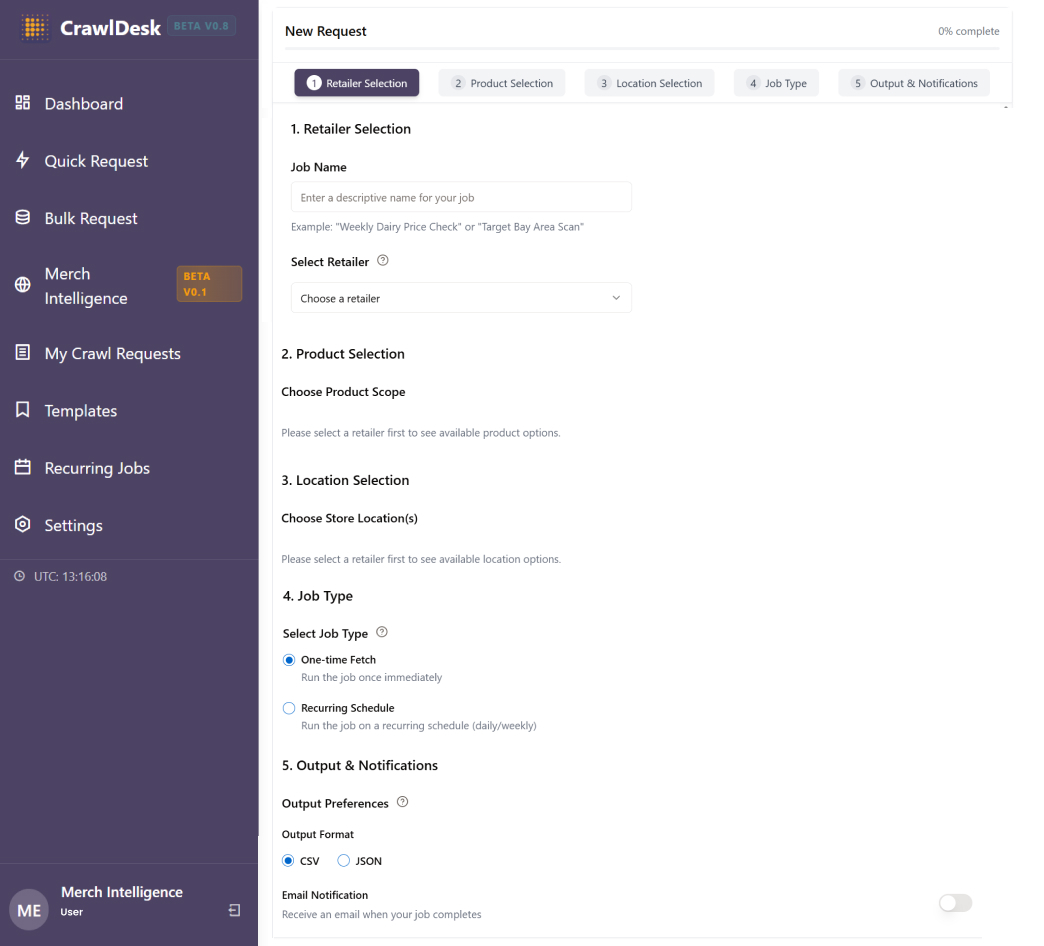
Here are the key features that Merch Intelligence brings to the table:
- Fully automated, end-to-end pipeline: No manual intervention required at any stage, from crawl to analysis to export.
- Dynamic attribute selection: Users choose which attributes matter most for their benchmarking exercise rather than being locked into a fixed schema.
- Confidence scoring on every data point: Full transparency on data quality, so teams know exactly how much weight to give each result.
- Multi-source comparison in a single view: Pricing, ratings, and normalized attributes across retailers, side by side.
- Flexible filtering and sorting: Results can be filtered by retailer, brand, subtype, price range, stock status, and minimum rating.
- Built for scale: Supports concurrent users and multiple simultaneous queries, so it grows from a pilot team to a broader rollout without rearchitecting anything.
How the process works:
Merch Intelligence runs a step-by-step process that takes a simple keyword search query and returns a ranked, structured competitive shortlist.
- Schema Detection: The AI identifies the canonical product type from the user’s keyword. A search for “air purifier,” for instance, gets mapped to “HEPA Air Purifier,” which determines the relevant attribute schema (CADR rating, room coverage, filter type, and so on). Each attribute is tagged by its role: price driver, buyer signal, or shelf differentiator.
- Multi-Source Crawl: The system simultaneously searches and fetches results across all selected retailers, pulling live product data as it appears to consumers.
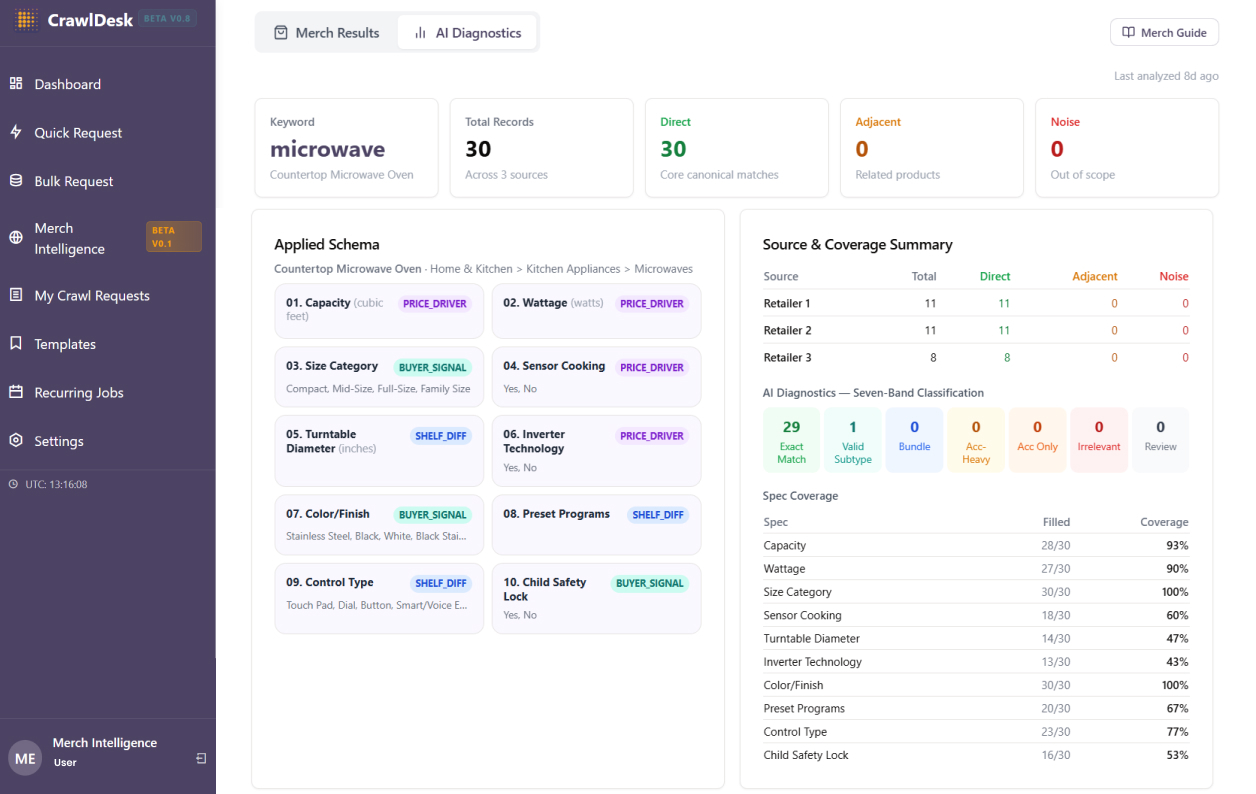
- AI Classification: Every result is classified into one of seven relevance bands: Exact Match, Valid Subtype, Adjacent Bundle, Accessory Heavy, Accessory Only, Irrelevant, or Needs Review. This classification is what separates useful results from noise before any analysis begins.
- Spec Extraction: For relevant products only, the AI extracts structured attributes and normalizes them into a consistent schema, regardless of how each retailer chose to label or organize the data on their pages. The system also calculates a Key Spec Fill Rate for each attribute, showing what percentage of products have that specification filled, so users can see at a glance where spec coverage is strong and where it’s thin.
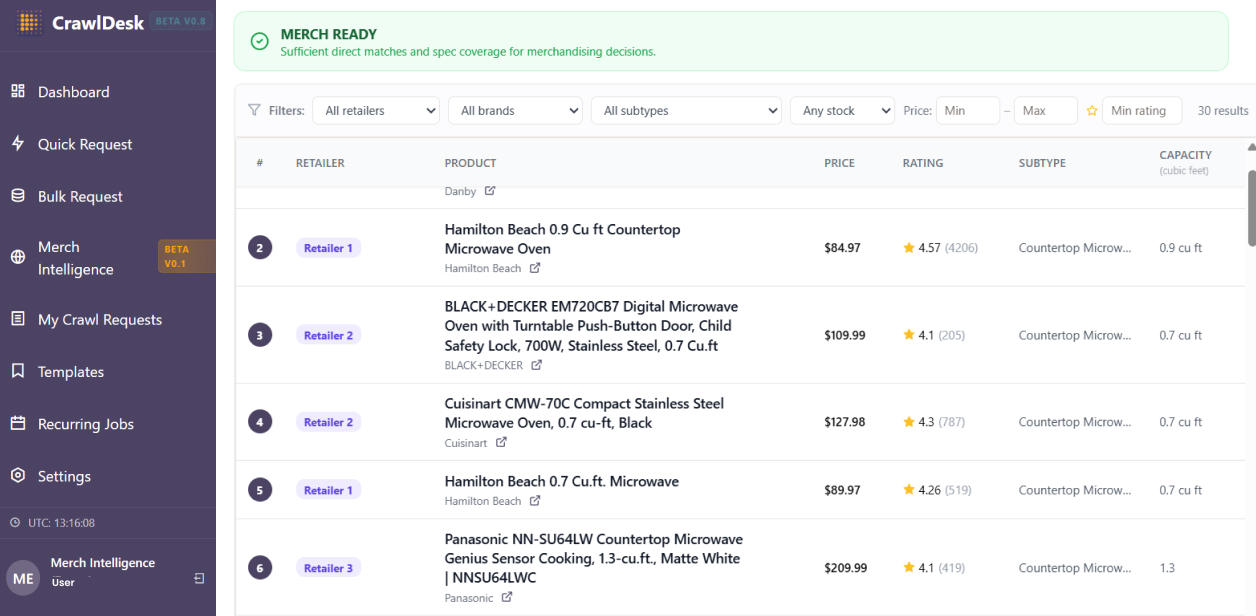
- Ranked Output: Products are ranked by a composite score that factors in relevance, spec completeness, rating, stock availability, and price. The final output flags each result set as either “Merch Ready” (sufficient direct matches and spec coverage for merchandising decisions) or “Needs Review.” Users can export curated results or the full raw dataset as a CSV.
The Workflow in Practice
The end-to-end experience for a user is straightforward.
Stakeholders who need a competitive data feed log in to the Data Collection API, set up a crawl job (one-time or recurring), select their retailers and geographies, and get a structured output delivered automatically. They can run a quick price check on specific UPCs, scan an entire category, or monitor key SKUs across multiple store locations, and the platform handles scheduling, alerting, and recovery without any manual oversight.
A merchandising team member who needs competitive analysis enters a product keyword, selects the retailers they want to benchmark against, and lets Merch Intelligence do the rest. The system crawls, classifies, extracts, scores, and returns a structured output grouped by retailer. The export includes a standardized set of fields: product name, brand, price, rating, review count, direct URL, subtype classification, and up to 10 normalized spec attributes aligned across all retailers. The file is ready to import into any planning tool without reformatting.
What previously took hours of manual searching, copy-paste work, and offline normalization now takes a single query and a few minutes.
The Impact
For this retailer, the competitive benchmarking exercise that used to take a day or more to assemble now takes minutes.
The Data Collection API gave the team on-demand access to ready-to-use competitive data across retailers, structured and normalized without any manual cleanup. Category managers could pull a pricing snapshot before a planning meeting, track category shifts on a weekly schedule, or monitor SKU-level changes across store locations, all self-serve, all in minutes.
Merch Intelligence took it a step further, delivering AI-powered actionable insights that told the team not just what competitors were doing, but what it meant for their own catalog. They could see at a glance where competitor products were outperforming on specs, where gaps existed in the market, and where price points suggested room to move. The confidence scoring and Merch Ready flagging meant they could trust the analysis without running a secondary validation step.
Together, the two layers changed how the team approached benchmarking altogether. Planning conversations became more grounded. Product briefs got more specific. Decisions moved faster.
The Takeaway
The challenge this retailer faced isn’t unique. Across retail and brand organizations, category managers and merchandising teams are stuck between two options that don’t work well enough: manual research that’s slow and incomplete, or generic AI tools that scrape data and run it through an LLM with no domain expertise.
DataWeave’s self-serve platform offers a different path. A real-time Data Collection API that delivers structured competitive data on demand or on schedule. And an AI-powered Merch Intelligence solution, built on years of retail domain expertise, that turns that data into analysis teams can actually act on. Both accessible directly by the people who need them, without intermediaries.
Once that foundation is in place, competitive intelligence stops being a research project and starts being a routine capability. That’s the shift DataWeave enables. Reach out to us to learn more.




Book a Demo
Login
For accounts configured with Google ID, use Google login on top.
For accounts using SSO Services, use the button marked "Single Sign-on".