
Why Retail Data Lakes Need A Different Blueprint
20th May, 2026

By Sadananda Vaidya
A grocery category manager at a mid-sized brand walks into Monday with a simple-sounding question: how is my private-label detergent priced against the top three competitors across our five biggest retailers this week? The answer is sitting somewhere inside a data lake. The path that question takes through the lake: how raw retail data is stored, processed, and served back as a usable answer, is the difference between a five-minute decision and a five-day investigation. Most retail data lakes today are built for the latter.
This is the first of three posts on what a competitive intelligence platform should look like when it is built from the data layer up. It is written for technology and business leaders inside CPG and retail organizations who keep wondering why their analytics keeps disappointing them, and what it should actually look like underneath.
The traditional shape of a retail data lake
Most retail data platforms in the field today carry the genetic markers of how big-data infrastructure was built a decade ago. Crawled product data, pricing feeds, marketplace assortment files, and content payloads land as row-oriented files, typically compressed JSON, partitioned by source and date. Reports are written as Python scripts that combine these files into a single dataset and process them line by line. Compute is single-engine, almost always whatever happens to be installed first. Filters by source, vertical, or date still require reading entire files end-to-end. Every meaningful change in business logic is a code change, a review, and a deployment.
That approach was reasonable when retail data was small. It isn’t anymore.
According to a 2025 report from Drexel University’s LeBow College of Business, 64% of organizations cite data quality as their top data integrity challenge, 45% list inconsistent definitions and formats among their top concerns, and 67% don’t fully trust the data they use for decision-making.
Read carefully, those numbers aren’t really about analytics. They are about plumbing. Most retail organizations don’t have a missing-model problem. They have a the-data-underneath-the-model-can’t-be-trusted problem. And that problem has its roots in the data lake.
Where row-by-row file processing collapses
When you are running a few dozen reports against a few terabytes of crawled data, line-by-line Python on JSON files works. When you are running thousands of reports against hundreds of millions of data points refreshed daily, three failure modes show up in sequence.
- Throughput: Iterating JSON records one at a time in Python doesn’t just slow down linearly with crawl volume – it slows down faster than the team can scale the rest of the platform. Every retailer onboarded multiplies the work. Every new SKU added stretches every job a little further. At some point, daily becomes overnight, and overnight becomes “we’ll have it Tuesday.”
- Selectivity: A user’s question is almost never “give me everything.” It is “show me men’s denim, three retailers, last fourteen days, US only.” Without columnar storage and predicate pushdown, the engine has to read every full record and discard the ones the user didn’t ask about. The cost is paid not in lines of code but in compute hours and at retail scale, those hours get expensive quickly.
- Engine lock-in: If a report is written as a Python script tightly coupled to one runtime, migrating it to a more efficient engine, say Spark for the heavy lifting, SQL through a serverless query service for ad-hoc exploration, Python only where it still makes sense, is a manual, per-report engineering project.
A different blueprint: what a modern retail data lake looks like
A retail-grade data lake built for the next decade has four properties that the traditional shape does not.
- It is columnar and partitioned by default. Crawled data lands in Parquet (or a similar columnar format), partitioned by the dimensions retail users actually filter on: source, vertical, date, region. Filters by these dimensions skip entire row groups; queries that touched gigabytes of compressed JSON in the old world touch megabytes in the new one.
- It operates at the dataframe level, not the row level. Transformations are expressed as operations on the whole dataset at once. Engines optimize them. The same logic that used to iterate records in a slow loop now runs in vectorized passes. It is measurably faster, and easier to reason about.
- It is engine-agnostic. A given report shouldn’t care whether it runs on Spark, on Python, or as SQL through a serverless query service. The choice of engine is a deployment decision driven by volume and SLA, not a code rewrite. Configurations (read paths, write paths, transformation logic) live as data, not as code. Swapping engines becomes a config change, not a re-implementation.
- It is operated like a platform, not a pile of scripts. Tenant data lives in dedicated storage paths with project-level access controls. Backfills run as orchestrated workflows, not as multi-day manual exercises. Lineage is preserved end to end. Every entity in the curated layer can be traced back to the raw payload that produced it.
The picture below presents a bird’s eye view. The four lanes: ingestion, tiered storage, processing, and serving are deliberately decoupled, so each can be optimized for its own cost, SLA, and quality profile.
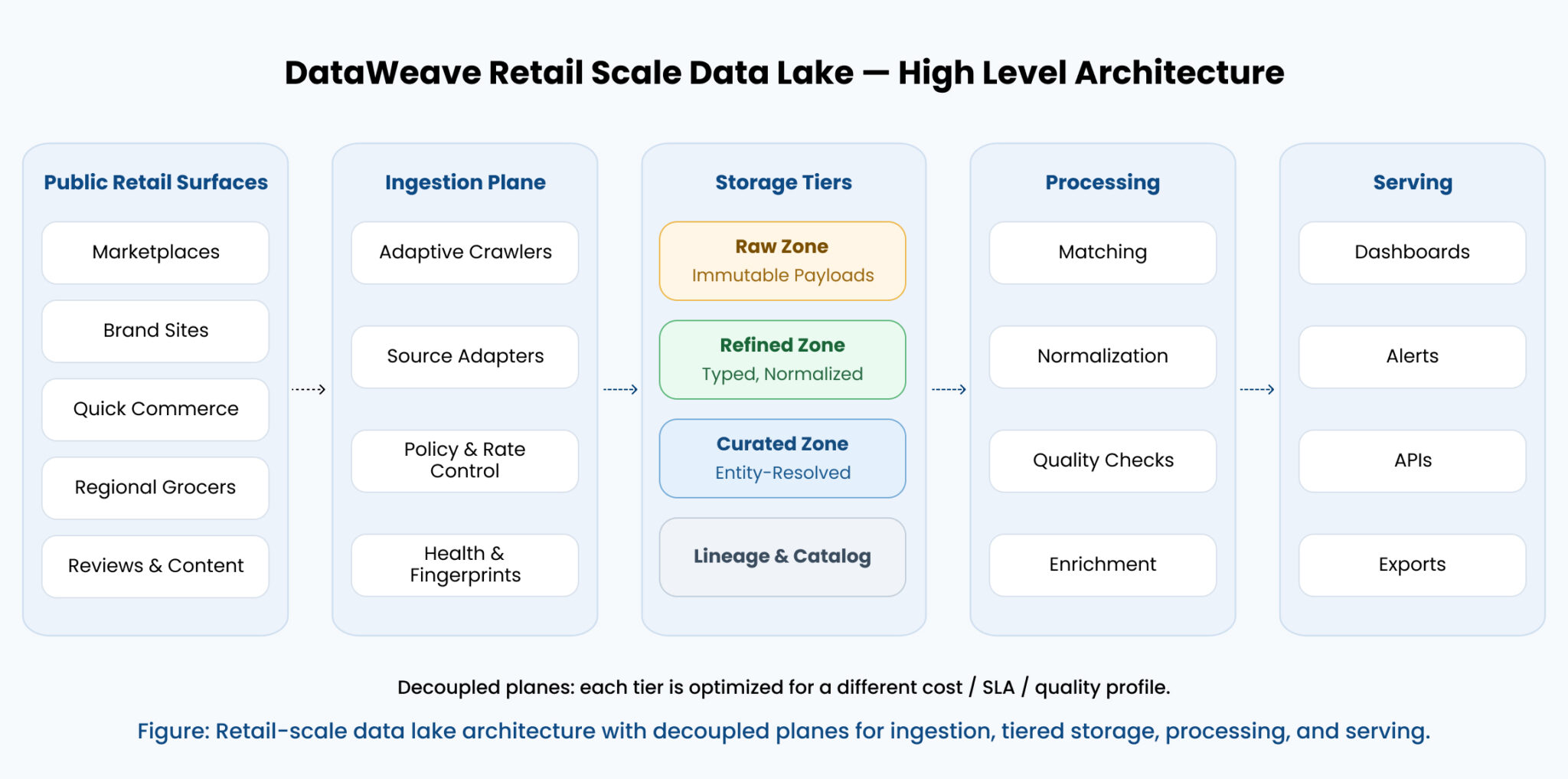
Why this matters to brands and retailers, not just engineers
A brand director reading this might fairly ask why an engineering blueprint should appear on her radar. The answer is that the questions retail leaders ask: “are we losing share on private label this week,” “is anyone selling our hero SKU below MAP,” “are my new launches outperforming last quarter’s” all bottom out in the data lake. When the lake is fast and trustworthy, those questions get answered in the time it takes to grab coffee. When it isn’t, they become quarterly projects.
The retailers and brands that will pull ahead over the next few years won’t be the ones with the most AI tools. They will be the ones whose data foundations are reliable enough that the AI tools they buy actually work. The blueprint matters because everything else sits on top of it.
This is first in a series articles – here we talk about the foundation layer. Stay tuned for our next post, where we’ll get into what sits on top of it: how matched, normalized, and enriched data turns raw crawl output into competitive intelligence stakeholders can actually use. If your team is already feeling the weight of a data lake that wasn’t built for retail scale, reach out to us to learn more.




Book a Demo
Login
For accounts configured with Google ID, use Google login on top.
For accounts using SSO Services, use the button marked "Single Sign-on".