
Trust, Speed, and The AI-Ready Foundation: Tech-Leadership Perspective for CPG Brands and Retailers
26th Jun, 2026

By Sadananda Vaidya
Following our exploration of the ideal retail data lake foundation and our deep dive into solving product identity at scale, this third and final instalment addresses the ultimate destination: turning that data foundation into agentic workflows.
Three years ago, inconsistent product data was a reporting annoyance. Dashboards took longer to build, match rates were lower than they should have been, category reviews involved more manual cleanup than anyone wanted to admit. Today, the stakes have shifted in kind, not just in degree. AI agents are no longer just surfacing insights for humans to act on. They are starting to act autonomously.
McKinsey estimates that agentic commerce could orchestrate $3 trillion to $5 trillion of global consumer commerce by 2030. Adobe’s research, cited by Nielsen IQ, found that AI-sourced traffic to US retail websites surged 1,200% year over year, and AI-referred shoppers convert 31% more than those arriving from other sources. OpenAI launched its Agentic Commerce Protocol with Stripe in 2025; Google introduced the Universal Commerce Protocol at NRF 2026 alongside Shopify, Walmart, Target, and Wayfair. EMARKETER forecasts that AI platforms will account for $20.57 billion in US retail e-commerce sales in 2026, nearly quadrupling 2025 figures.
Pulled together, those data points say one thing very clearly to engineering and business leaders alike: bad data is about to start producing bad autonomous decisions at scale. A recommendation engine can absorb occasional uncertainty, a shopper either accepts the suggestion or ignores it. A purchasing agent cannot. The moment AI transitions from helpful guide to action-taker, the platform is judged on whether it is correct, not on whether it sounds confident.
This third post is about what comes after normalization: the platform capabilities that turn clean, matched data into trustworthy retail intelligence the rest of the business, and the AI agents working on its behalf, can actually rely on.
Where traditional retail-intelligence stacks fall short
A common pattern in retail intelligence platforms looks something like this. Crawl jobs run overnight. A batch of reports runs against the resulting files. Output flows into dashboards. Customers find anomalies, file tickets, wait for backfills, lose trust. Every new report is engineering work. Every metric question that needs a slightly different cut is engineering work. Cross-tenant safety is managed by convention more than by design.
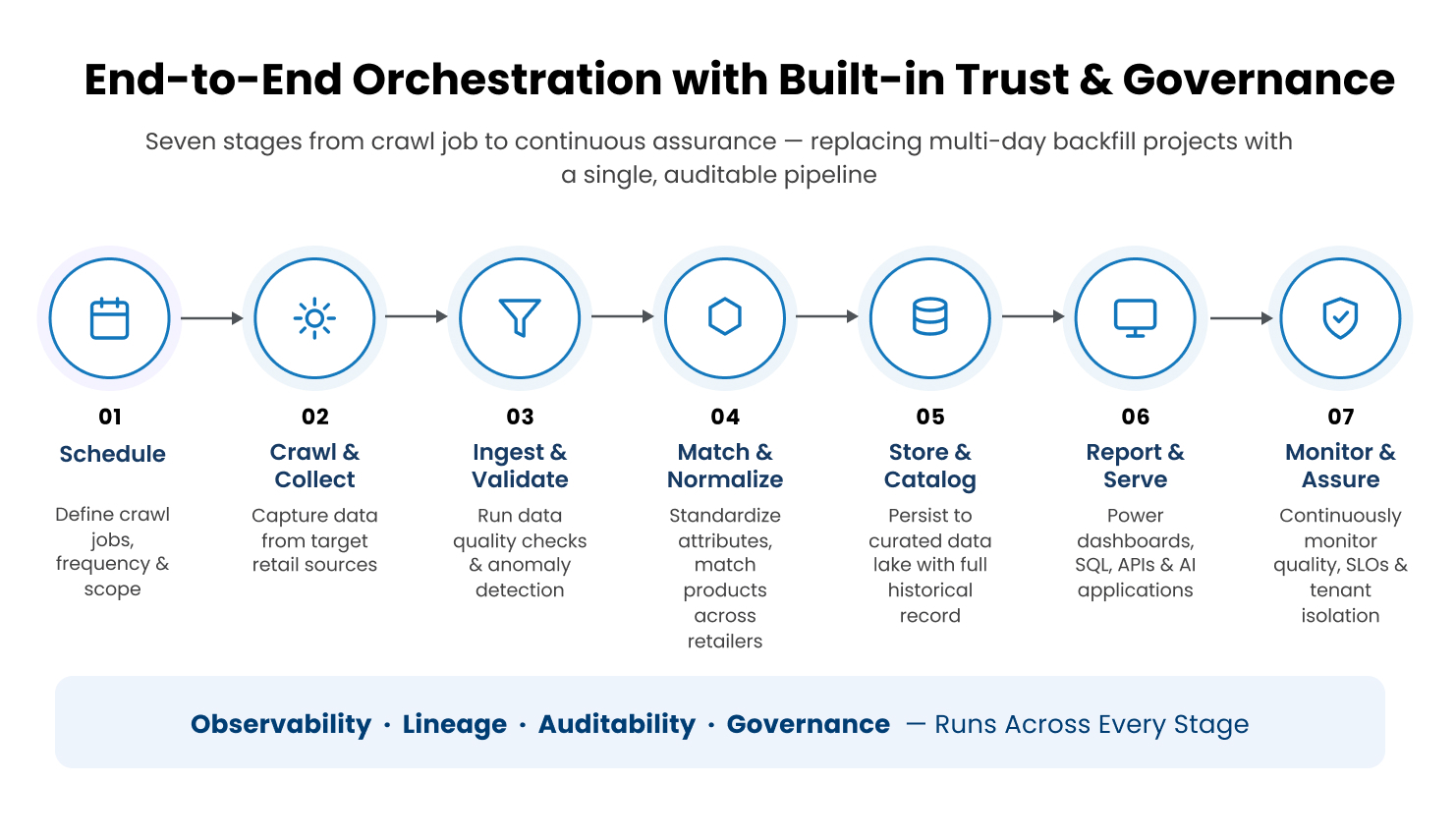
That pattern was workable when retail moved on a weekly rhythm and customers tolerated three-day investigations. It does not work in a world where pricing changes multiple times a day and an AI agent is expected to recommend a competitive response inside the hour. Insight latency is now a competitive metric, and so is data trust.
The platform capabilities a modern retail-intelligence foundation needs
A modern retail-intelligence platform has to provide these kinds of capabilities reliably. Each one looks like a tactical engineering choice up close and a strategic differentiator at a distance.
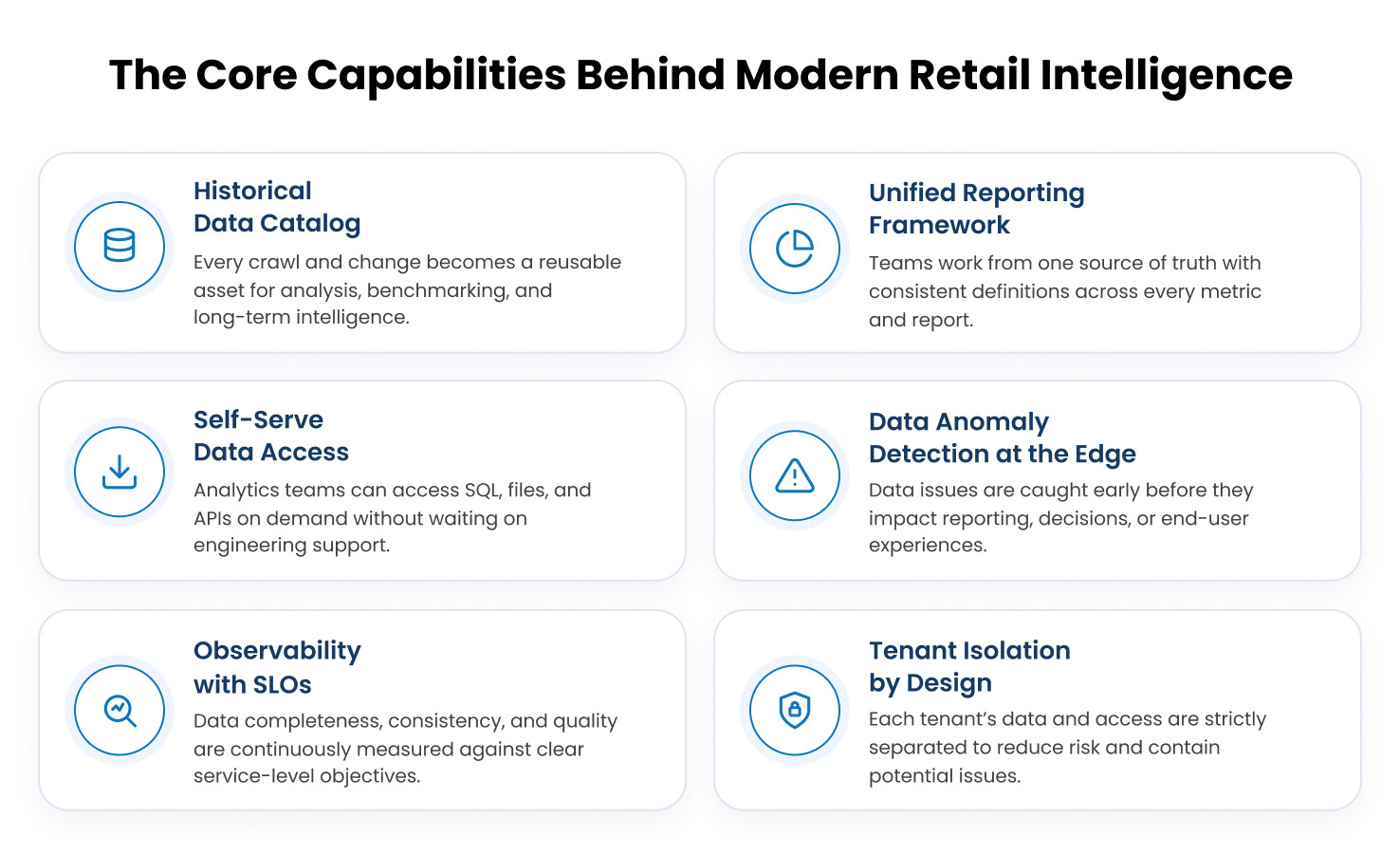
- A historical data catalog: The crawled record of the retail web (every price, every assortment shift, every content update) is a reusable asset, not a one-time input to a single report. Treating it as a catalog means trend analysis and historical comparisons stop being a re-crawl exercise, repeated work disappears, and the underlying data becomes a reusable foundation for ML and AI models built on top of it.
- A unified reporting framework that serves as a single source of truth: When standard and custom reports each reconstruct the world independently, metric drift is inevitable. The same KPI ends up with three subtly different definitions, customers stop trusting which number is right, and the engineering team loses days mediating between dashboards. A unified reporting layer fixes this at the platform level with the same metric definitions, same matched entities, same lineage, every time.
- Self-serve data access: Not every customer question is best answered by a dashboard. Some are SQL questions, some are file downloads, some are programmatic API calls. Exposing the curated layer of the data lake to customers through SQL via Athena and direct file access via S3 lets analytics teams inside CPG and retail organizations move at their own pace, without filing a ticket for every cut. Engineering becomes a platform team, not a bottleneck.
- Data anomaly detection at the edge: The cheapest place to catch a bad record is before it ever lands in a customer’s dashboard. Statistical and rule-based anomaly detectors that flag missing or corrupt records at ingestion time stop bad data before it reaches the customer, reduce downstream firefighting, and produce a measurable lift in trust.
- Observability with SLOs that can actually be reported: Completeness, consistency, and quality are not things you check by sampling. They are properties the platform measures continuously and surfaces — to the engineering team, to the customer success team, and to customers themselves. Service-level objectives stop being a marketing word when the system can actually report against them.
Underneath all six capabilities sits a tenant-isolation model that takes safety seriously. Each customer or project has dedicated storage paths with read/write access granted at the user or project level. There is no implicit cross-tenant access, and the blast radius of any incident is bound to the tenant that produced it. Customer-owned data flows into the curated layer with the same care, joined cleanly to crawl data as input to reports, never mingled implicitly with other tenants’ inputs. End-to-end orchestration turns what used to be multi-day backfill projects into a single, audit-able ticket.
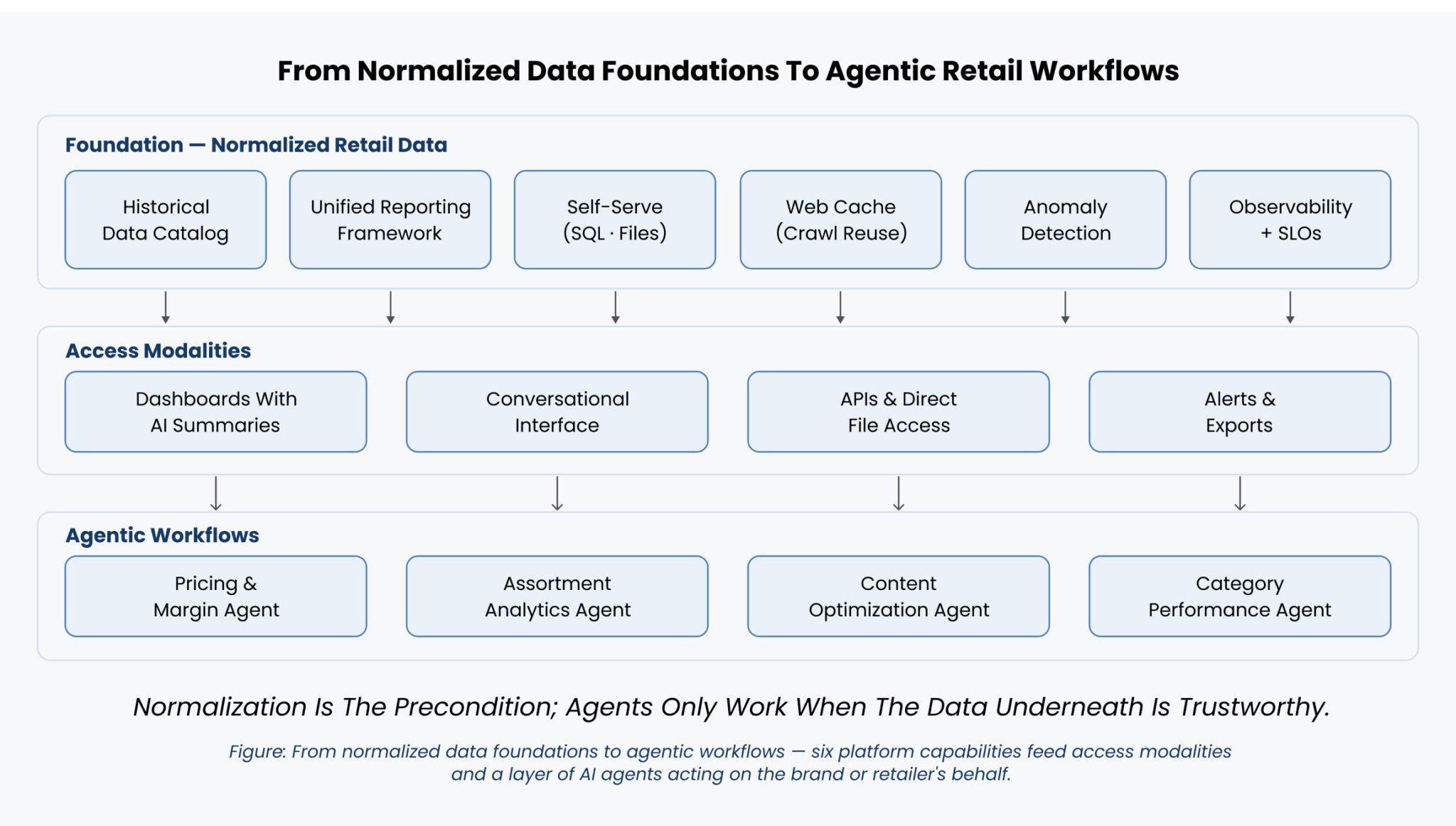
Turning the foundation into agentic workflows
Once the foundation is clean, the question becomes how customers should interact with it. There are three surfaces, in increasing order of autonomy.
The first surface is AI summaries on existing dashboards. Instead of expecting a category manager to scan a trend line, interpret it, and draw conclusions, the system provides the interpretation upfront. Pre-computed narrative insights surface automatically, before the user asks a question.
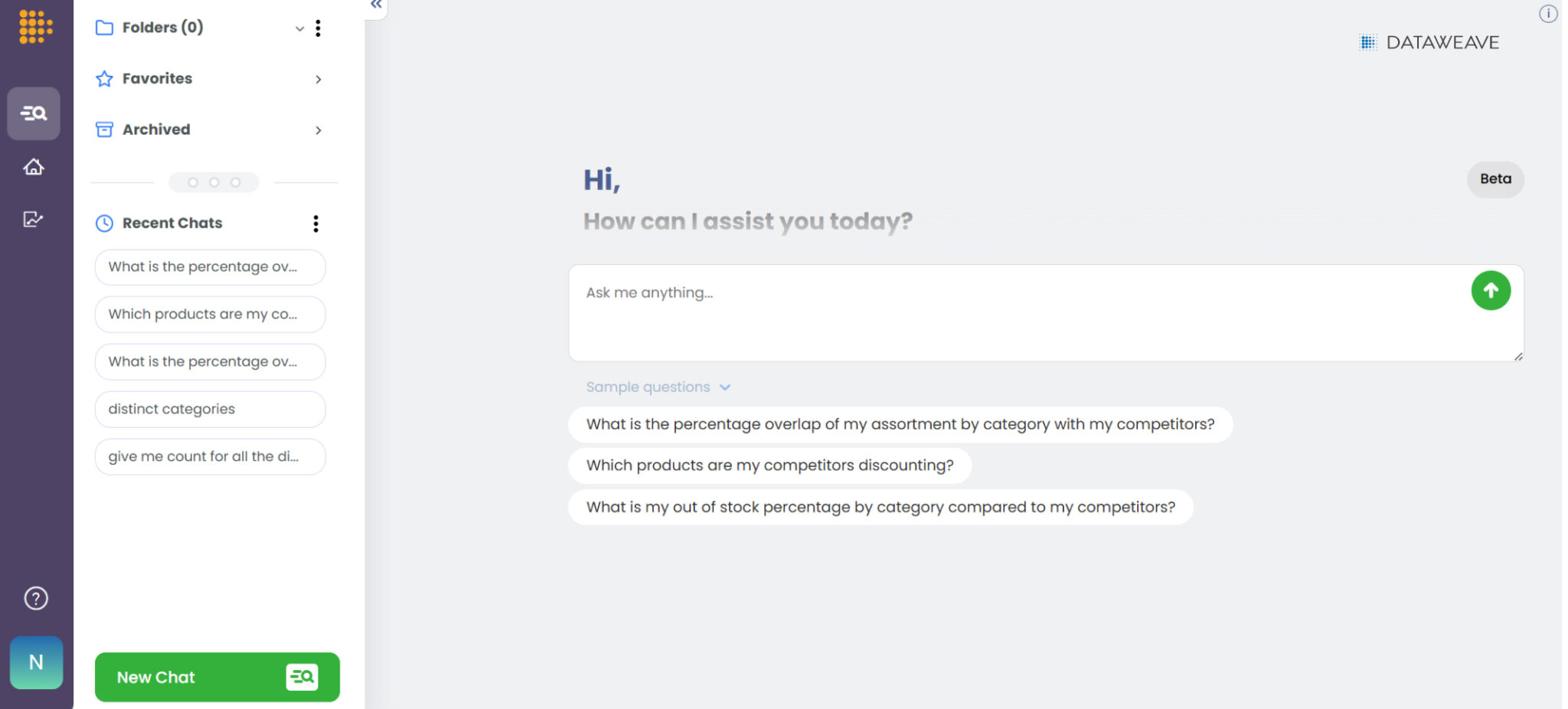
The second surface is the conversational interface. Instead of clicking through filters to find an assortment gap, a user can ask “where do I have the biggest assortment gap in this price range for this category?” and get a direct answer with the underlying visualization.
The third surface is agentic workflows, and this is where the years of work on normalization pay off most visibly.
- A pricing and margin agent scans competitive price positions weekly, identifies outliers, and generates SKU-level recommendations: “Decrease price on top SKUs in core denim by 5–7% to maintain parity with Retailer Y and protect traffic on relevant keywords,” or “Increase price on designer bags and boots by 3% — you’re 8% below the market, and elasticity history suggests neutral impact on demand.”
- An assortment analytics agent scans competitor catalogs to identify gaps, overcrowded segments, and emerging brands winning share of search or ratings momentum, and recommends additions or rationalizations with specific SKU counts and share targets . For instance, “add 12 SKUs in premium denims where you have 2% catalog share versus market 12%,” or “rationalize 20 SKUs in long-tail where your sales are below threshold and price gaps are minimal.”
- A content optimization agent evaluates PDP readiness, benchmarks against competitors, and generates category-specific fixes: “standardize rise, inseam, leg opening, and stretch percentage; ensure fit keywords in title; add back-view and fabric close-up images. This improves filter match and share of search for core denim terms.”
- A category performance agent summarizes KPIs across price position, new product entry, content quality, and reviews and sentiment, benchmarks against named competitors across channels, and auto-generates narrative summaries with charts for leadership presentations.
None of these agents work without the normalization layer underneath. The pricing agent can’t compare prices if it doesn’t know which products match across retailers. The assortment agent can’t identify gaps if taxonomies aren’t aligned. The content agent can’t benchmark without standardized attribute tags. The category agent can’t aggregate without consistent definitions across the underlying data.
That 87% of data science projects never reaching production? Most of them aren’t failing because of bad models. They’re failing because of bad data.
The retailers and brands that thrive in this next era won’t be the ones who buy the most AI. They will be the ones whose data foundations are clean, governed, observable, and self-serve enough that AI (bought, built, or partnered) can actually do its job. That foundation isn’t a feature. It is the product.
This third and final post brings our series full circle. From rethinking the underlying architecture of your data lake in part one to mastering multimodal product identity in part two, we have mapped out what a truly modern, retail-intelligence platform requires to withstand the scale of the agentic era. The journey from messy data to autonomous workflows is neither short nor simple, but it is the ultimate differentiator for brands and retailers looking to lead over the next decade.
If your organization is ready to move past brittle pipelines and build a clean, observable, and fully AI-ready retail data foundation, reach out to us to learn how we can transform your data infrastructure together.



Book a Demo
Login
For accounts configured with Google ID, use Google login on top.
For accounts using SSO Services, use the button marked "Single Sign-on".